Wednesday, April 18, 2012
045 - A nondeterministic note about nondeterminism
This blog note has been moved to http://www.teigfam.net/oyvind/home/049-nondeterminism/ on 7 Nov 2012.
Wednesday, March 21, 2012
044 - Is (x < (x+1)) really always true?
- Update (16Sept2015): New blog note, similar theme: Know your timer's type
- Update (12April2012): one of the compiler vendors mentioned below has admitted to consider to make the compiler generate a #warning for the dead code examples here! So maybe it is possible to change the world, just a little?
One added to a number
Even if the value one added to any number is always greater than the number itself, this is not so when we work with finite word sizes in a program. The example code below shows some examples that should have a predefined semantics (but they don't seem to):
I would not program with an expression like on the left side! Also, I never use single letters for variables. But this is research, where this is legal for an hour.
A signed number would wrap around when "1" is added to it, from most positive 127 to most negative -128 (assuming 8 bit basic word length in these examples). An unsigned would wrap from its most positive 255 to 0. You must define the int.. and word.. types for yourself, and be sure that there is a greater value around it this would stop the loop (like my 300, which is more than 255 anyway). I do this so that I only have one complex ball in the air at a time. Research tries to divide and conquer.
Since 127 is not less than -128 (top left and right code - it's greater!) and 255 is not less than 0 (bottom left and right code - it's also greater!), my compiler should make the program hit the four breakpoints BP1-BP4 in turn. Right?
Not my compiler, optimized code or not! The program only hits BP3 and BP4! In the rightmost code, the variable "y" runs before "x" by "1", so all is fine. But in the leftmost code, the variable "x" incremented in the expression as "x+1" causes the compiler to get it wrong!
I tried to take control of the value "1" that's added by making a variable "one" with value "1" as signed or unsigned, but it did not help. I tried two variables that followed each other and "x < (y+1)", but it did not help. Finally I tried "(((x+1)-x)>0)", but still I never hit the false branches BP1-BP4!
Compilers
I compiled with the IAR compiler for an eight bit machine. We also compiled with gcc on Linux, and it's the same. I ran a test with static analysis tool QA·C from Programming Research with rather strict "personality", and it did not complain. I have not tested with PC-Lint.
The "excuse"
Of course there is an "excuse" for this in the C compiler world. How an expression is internally evaluated is not the programmer's business. He doesn't own the expression. This is so by language design.
So, if they use 16 bits to evaluate an 8 bit expression (there is nothing like an "8 bit expression", it's "their any-bit expression"), then it would not wrap around from 127 or 255, but get straight into 128 or 256. If there is width enough. But they will sooner or later get another semantics from the same syntax, as widths go from 8 to 16 to 32 to 64 - and wrap around is or is not inevitable!
(How about type casting inside the expression? In this case I could try to, but I would still have to test to know what happens - hugely unnecessary in 2012, almost 50 years after Fortran. WYSI-not-WYG! And besides, I had already used typed variables into the expression)
(This remembers me of a situation where I was going to make a single-bit mask by shifting into a word8, 16 or 32. In order to make a macro work, the one'er that I had to use was required to be typecast to a long. So the macro became #define MASK_F(c) (1L << c), observe the 'L'. The standard seems to state that it is supposed to be like this. The long typecast was required for the 32-bit mask, and did not hurt for the other masks. I wonder why this is intelligent language design)
Back to the not hitting false issue. There is a serious cognitive problem also here. Any programmer relates to word widths. They are always finite, like a ruler inside our heads, from one ear to the other.
We should hit all those breakpoints! But the state of the art is that we might probably not get there.
We would never know, a priori. But this is as precise as it gets: we'd have to think about this expression is a bubble.
(PS, if you are still with me. My starting sentence "Even if the value one added to any number is always greater than the number itself" is about as precise as I could make it..)
.
typedef signed char int8_a;
typedef unsigned char word8_a;
typedef unsigned short word16_a;
#define MAX 300
word16_a cnt;
{
// -------- signed --------
{
int8_a x = 0;
cnt = 0;
//
while (cnt < MAX)
{
if (x < (x+1))
{
cnt = cnt + 1;
}
else
{
cnt = MAX; // BP1
}
x = x + 1;
//
}
}
// -------- unsigned --------
{
word8_a x = 0;
cnt = 0;
//
while (cnt < MAX)
{
if (x < (x+1))
{
cnt = cnt + 1;
}
else
{
cnt = MAX; // BP2
}
x = x + 1;
//
}
}
}
| // Øyvind Teig
// Trondheim
// Norway
//
//
{
// -------- signed --------
{
int8_a x = 0;
int8_a y = 1;
cnt = 0;
while (cnt < MAX)
{
if (x < y)
{
cnt = cnt + 1;
}
else
{
cnt = MAX; // BP3
}
x = x + 1;
y = y + 1;
}
}
// -------- unsigned --------
{
word8_a x = 0;
word8_a y = 1;
cnt = 0;
while (cnt < MAX)
{
if (x < y)
{
cnt = cnt + 1;
}
else
{
cnt = MAX; // BP4
}
x = x + 1;
y = y + 1;
}
}
}
|
A signed number would wrap around when "1" is added to it, from most positive 127 to most negative -128 (assuming 8 bit basic word length in these examples). An unsigned would wrap from its most positive 255 to 0. You must define the int.. and word.. types for yourself, and be sure that there is a greater value around it this would stop the loop (like my 300, which is more than 255 anyway). I do this so that I only have one complex ball in the air at a time. Research tries to divide and conquer.
Since 127 is not less than -128 (top left and right code - it's greater!) and 255 is not less than 0 (bottom left and right code - it's also greater!), my compiler should make the program hit the four breakpoints BP1-BP4 in turn. Right?
Not my compiler, optimized code or not! The program only hits BP3 and BP4! In the rightmost code, the variable "y" runs before "x" by "1", so all is fine. But in the leftmost code, the variable "x" incremented in the expression as "x+1" causes the compiler to get it wrong!
I tried to take control of the value "1" that's added by making a variable "one" with value "1" as signed or unsigned, but it did not help. I tried two variables that followed each other and "x < (y+1)", but it did not help. Finally I tried "(((x+1)-x)>0)", but still I never hit the false branches BP1-BP4!
Compilers
I compiled with the IAR compiler for an eight bit machine. We also compiled with gcc on Linux, and it's the same. I ran a test with static analysis tool QA·C from Programming Research with rather strict "personality", and it did not complain. I have not tested with PC-Lint.
The "excuse"
Of course there is an "excuse" for this in the C compiler world. How an expression is internally evaluated is not the programmer's business. He doesn't own the expression. This is so by language design.
So, if they use 16 bits to evaluate an 8 bit expression (there is nothing like an "8 bit expression", it's "their any-bit expression"), then it would not wrap around from 127 or 255, but get straight into 128 or 256. If there is width enough. But they will sooner or later get another semantics from the same syntax, as widths go from 8 to 16 to 32 to 64 - and wrap around is or is not inevitable!
(How about type casting inside the expression? In this case I could try to, but I would still have to test to know what happens - hugely unnecessary in 2012, almost 50 years after Fortran. WYSI-not-WYG! And besides, I had already used typed variables into the expression)
(This remembers me of a situation where I was going to make a single-bit mask by shifting into a word8, 16 or 32. In order to make a macro work, the one'er that I had to use was required to be typecast to a long. So the macro became #define MASK_F(c) (1L << c), observe the 'L'. The standard seems to state that it is supposed to be like this. The long typecast was required for the 32-bit mask, and did not hurt for the other masks. I wonder why this is intelligent language design)
Back to the not hitting false issue. There is a serious cognitive problem also here. Any programmer relates to word widths. They are always finite, like a ruler inside our heads, from one ear to the other.
We should hit all those breakpoints! But the state of the art is that we might probably not get there.
We would never know, a priori. But this is as precise as it gets: we'd have to think about this expression is a bubble.
(PS, if you are still with me. My starting sentence "Even if the value one added to any number is always greater than the number itself" is about as precise as I could make it..)
.
Wednesday, March 7, 2012
043 - Scratching my head with their HATS
HATS stands for Highly Adaptable and Trustworthy Software using Formal Models and is an Integrated Project supported by the 7th Framework Programme of the EC within the FET (Future and Emerging Technologies) scheme, quoting from [1].
[Lots of words here that I have removed and saved but perhaps may come back to. If you look at some of the references you may get an idea why I thought it difficult to extract concurrency related features. This is very comprehensive stuff!]
[2] - http://www.teigfam.net/oyvind/pub/pub
[7] - http://www.hats-project.eu/sites/default/files/Deliverable25.pdf -" Deliverable D2.5- Verification of Behavioral Properties"
Since I have worked in a company with concurrency in a lifetime [2], and also touched the formal language Promela and verified with Spin [3] - and worked with CSP-based channel based concurrency for half a life [4] - HATS recently caugth my interest.
[8March2012: This note became unmanagable for me, so I have parked it for the time being. I'll apply for a refill of brains and maybe come back. Sorry]
[8March2012: This note became unmanagable for me, so I have parked it for the time being. I'll apply for a refill of brains and maybe come back. Sorry]
[Lots of words here that I have removed and saved but perhaps may come back to. If you look at some of the references you may get an idea why I thought it difficult to extract concurrency related features. This is very comprehensive stuff!]
References
[2] - http://www.teigfam.net/oyvind/pub/pub
[6] - http://www.hats-project.eu/sites/default/files/Deliverable11a_rev2.pdf - "HATS Deliverable D1.1A Report on the Core ABS Language and Methodology: Part A"
[7] - http://www.hats-project.eu/sites/default/files/Deliverable25.pdf -" Deliverable D2.5- Verification of Behavioral Properties"
.
.
Monday, February 27, 2012
Saturday, February 4, 2012
040 - Amateur publishing for real
1. From Apple Pages to iPhoto and your own paper book
I have now for the second time used Apple Pages and iPhoto to make my own books. Apple calls what I order for an Apple print product. This note will share some of that experience with you. (My books are in Norwegian and may be seen here, soon also the new book).
The general problem is that when you get a book in paper (from any manufacturer, I assume - not just Apple), the machines have to cut the paper after printing. In this case the manufacturer needs individual sheets, since the book I ordered is glued. So the spine end needs to be cut. And the book needs to be cut after it has been bound (glued), so that the three other sides get ok. Of course I don't get what I see, there is not really any WYSIWYG book production. Then we amateurs enter, and assume that we should understand book production, after 600 years of professionalism.
iPhoto's book assembly tool is heavily based on theme templates, with large portions of neutral parts around the edges. My pictures are automatically placed, or I pick and place them into predefined windows by hand. This may be difficult, since iPhoto (unlike Pages), does not seem to have any scale to fit or scale to fill options. For me this was a problem with the rear cover (more later).
But in my case the major problems come with the 1 picture possibility, where the whole page is mine! I love the option, but I hate the guessing.
With a full picture page iPhoto basically has these options:
- Fit to frame (tick on or off: I did off) ("Tilpass bilde til rammestørrelse" in Norwegian)
- Moving picture around by hand (I did push to right on right pages and push to left on left pages)
I guess the reason for the few choices is the complexity of cutting, as just outlined. For the front cover I did not do fit to frame, since I want (as much as possible) the top and bottom not to be cut. iPhoto crops the sides this way. When the book arrived I saw that it was not 20 cm wide, but 19.5 cm. If I had ticked fit to frame, I still don't think that they would have cut the height and kept the width. The option, I believe is for iPhoto, not production cuts.
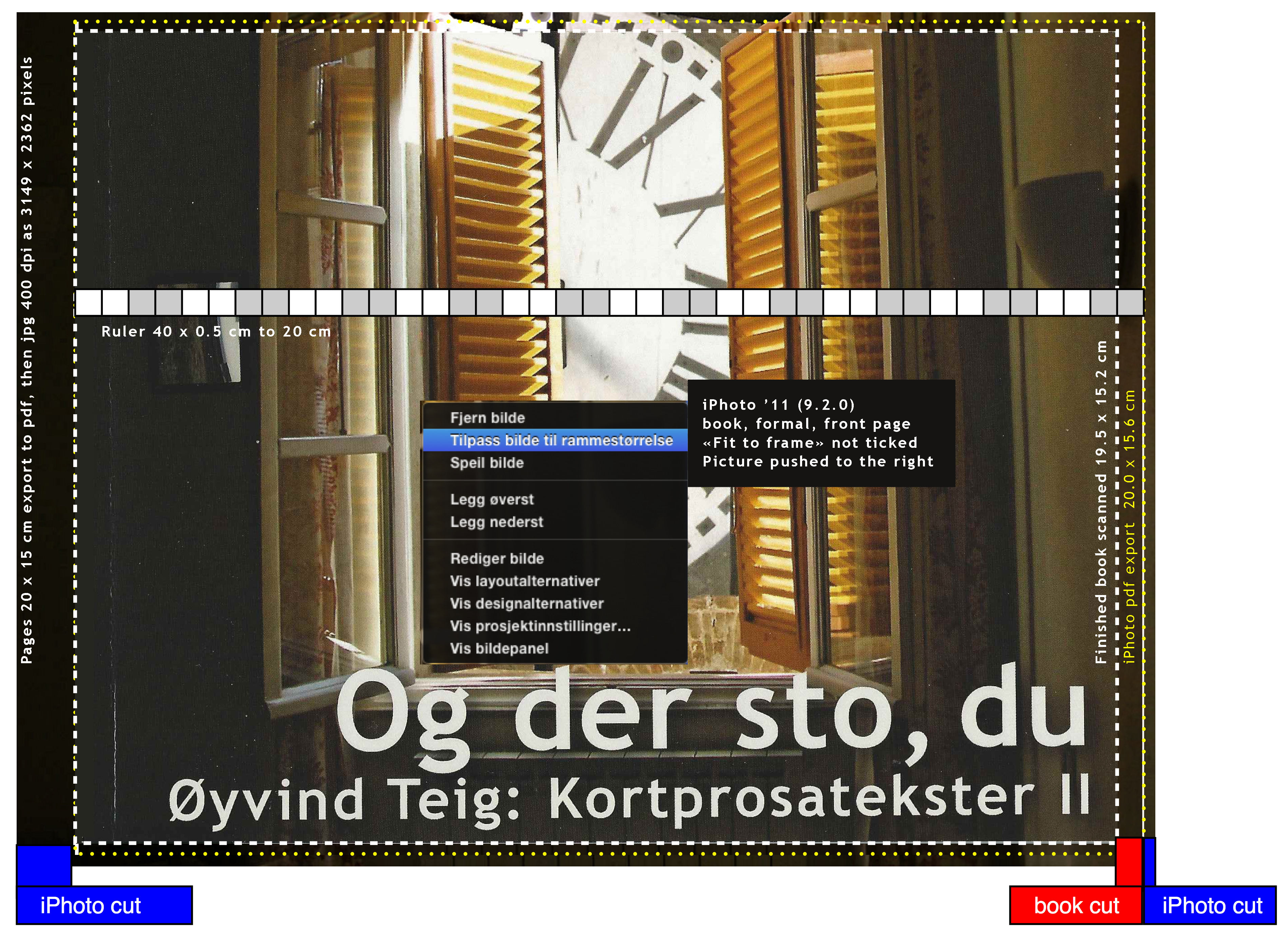
Here is my front cover. There is a higher resolution here. It shows iPhoto '11 9.2.0:
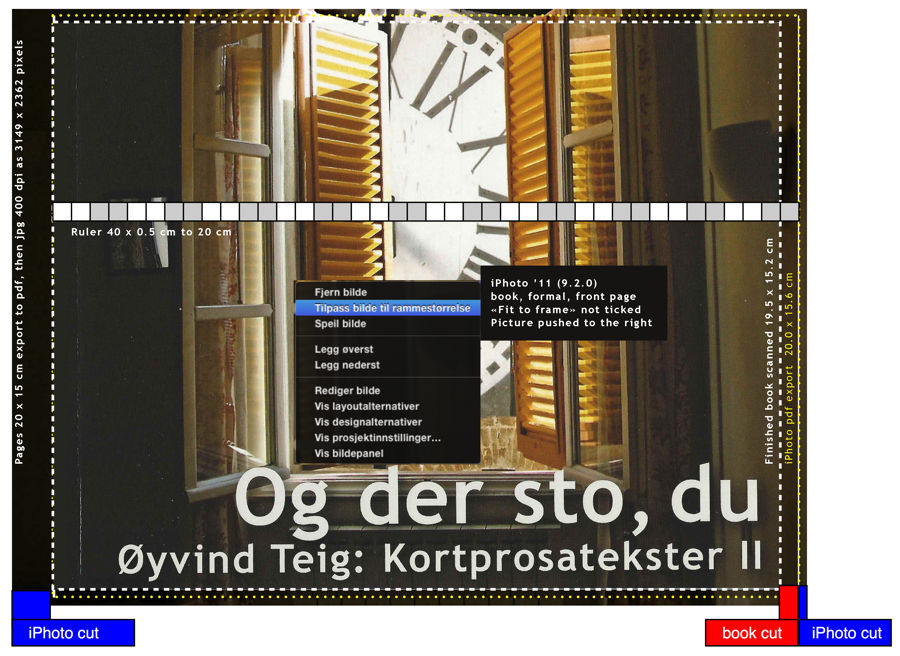 I tried to figure out beforehand, but I could not find a figure like the above. Only complaints that there was none. There certainly are iPhoto forums and books, like iPhoto '11: The Missing Manual, there may be pictures like this there. Anyhow, the picture shows where my pixels go!
I tried to figure out beforehand, but I could not find a figure like the above. Only complaints that there was none. There certainly are iPhoto forums and books, like iPhoto '11: The Missing Manual, there may be pictures like this there. Anyhow, the picture shows where my pixels go!Observe the 0.5 cm graded ruler, starting at the book spine. The outer picture is the original (outer on all sides), aligned correctly on top of the book. It would have its own ruler, which is not show here, not to confuse.
 There are some problems. The first problem arises from the fact that Apple does some edge fading of the graphics. Probably nice for a picture, but not for an ISBN-13 barcode. The second problem is the limited handling: I can only scale up (not "smaller" from the original) with a slider, and push the picture left or right. In the picture you see that it's not aligned correctly in the middle yet. The third problem is the missing scale to fit or scale to fill. And the fourth is that I don't know how scaling & fitting is done initially. But I still assume that the tool designers at Apple have had their reasons for these design choices: probably to make standard handling as easy as possible.
There are some problems. The first problem arises from the fact that Apple does some edge fading of the graphics. Probably nice for a picture, but not for an ISBN-13 barcode. The second problem is the limited handling: I can only scale up (not "smaller" from the original) with a slider, and push the picture left or right. In the picture you see that it's not aligned correctly in the middle yet. The third problem is the missing scale to fit or scale to fill. And the fourth is that I don't know how scaling & fitting is done initially. But I still assume that the tool designers at Apple have had their reasons for these design choices: probably to make standard handling as easy as possible.

My last book contains 24 short stories, so it has text and pictures. I start by getting ISBN numbers for free from the Norwegian National Library (Nasjonalbiblioteket, ISBN-kontoret). Since I make paper, pdf an ePub, I get three ISBN numbers.
This first chapter discusses the paper production.
First I must say that these books are expensive. But for the limited editions I seem to do, I haven't found any better deals.
Here's how I go ahead:
- I write the book in Pages on a Mac. I use page layout when the goal is paper or pdf. Page size 20 cm width x 15 cm height, since that's one of the formats that iPhoto book has. The picture above shows that the physical book I got back was 19.5 x 15.2 cm.
- I export to pdf, best quality. I get one pdf.
- I open this pdf in GraphicConverter as 400 dpi and export from GC. It will make jpg of all my pages in one batch. (In 2008 I could export directly from Pages to iPhoto, but it only yielded 200 dpi, which was not good enough for the 10 point text. Also, Preview for Lion does export to jpg any dpi you like, but only one page at a time).
- I import all my jpg images of my book pages to iPhoto. It has no idea that this is a book with short stories.
- I build the book and order it. This book uses formal layout and 20x15 cm softcover. But before that I iterate too many times, hence the figure above. The figure really says everything valid for my last order, the way it's described above.
- To iterate I use archive book as pdf from iPhoto (one pdf), and export as jpg (one jpg per page). I study and try and study. Next time I'll reread this blog note!
There are some things I'd like to be a little different (see some book terminology here).
- There is no title on the spine. I assume the books Apple produces often are too thin, so it's difficult to get the title correctly aligned at that cost.
- The rear cover has a defined format, with one or two predefined windows (one for bitmap and one for text, see next figure). The rest of the structure may be defined by a few choices. I assume it's because letting me do the rear cover myself with include knowledge of how thick the back (book) is.
1.1 Filling rear cover window
As mentioned I had to experiment a lot to find a correctly sized graphics file to paste into the rear cover window. Again, formal theme, and a layout with a window for graphics and one for text.
There are some problems. The first problem arises from the fact that Apple does some edge fading of the graphics. Probably nice for a picture, but not for an ISBN-13 barcode. The second problem is the limited handling: I can only scale up (not "smaller" from the original) with a slider, and push the picture left or right. In the picture you see that it's not aligned correctly in the middle yet. The third problem is the missing scale to fit or scale to fill. And the fourth is that I don't know how scaling & fitting is done initially. But I still assume that the tool designers at Apple have had their reasons for these design choices: probably to make standard handling as easy as possible.At first I made the graphics like I thought it should, thin and just enough white space. This did not fit, some part of it was lost. To make a long history short (I tried some 5-10 times), have a look at the graphics (top, right): much more right and left white space than I thought. The pixel width x height is 2669 x 2967 or 0.89. It's completely over-bitmapped, but iPhoto scales it down ok. I don't know if any 1:0.89 picture would do, but I assume so.
I assume that if I had used other layouts than 1 picture, the problems described here would go for scaling into any window on any page, not just the rear cover. But I haven't checked.
Reported to http://www.apple.com/feedback/iphoto.html 4Feb2012.
2. With Apple Pages towards export as ePub
I start with Apple's own descriptive sample file, referenced at http://support.apple.com/kb/ht4168 "Creating ePub files with Pages". Download their "ePub Best Practices" Pages document "Apple ePub Best Practices for Pages.pages".
(Later on you'll see that I'll verify the ePub with the validator provided by the International Digital Publishing Forum http://validator.idpf.org/ to check that I and Apple have done our jobs.)
Then I take my book, previously in a pages page layout document. I export it into a clean text file. Then I copy and paste from it, onto the Apple example document (as they suggest). Going through the clean text is time consuming, but so is figuring out the different styles that the ePub needs to have, but would clash with what I previously had in the original document.
Then I delete all contents and set page size to 20 x 15 cm. What page size means in this context, see next chapter.
Observe that Pages export to ePub will not treat any page break entries! Page breaks are not exported to ePub! Even if they are available in the menu. Pages would not know that you are going to export as ePub later on! This is an impedance mismatch, if you ask me. Pages has two main modes now: 1.) word processor and a 2.) page layout. It knows partly what your'r doing. Not so with ePub! (And the new "iBooks Author" won't solve it, as it does not export ePub, only pdf and ibooks formats. The latter is an extension to ePub.).
Have a look at ePub here: http://en.wikipedia.org/wiki/EPUB. You will see that ePub are text-centric flow based books. And no layout control. Page breaks are layout. There is a good explanation at https://discussions.apple.com/message/17543346#17543346 "Pages to ePub observations and hints" by israfelli.
So, Pages treats everyting that goes into the index as start of page. So, I use "Chapter name" style for this. When pictures are included, they are often glued to the chapter in some way.
2.1 Page and object sizes
Before you add any pictures, make sure to name them with old fashined ASCII only! See chapter 2.3.
Even if the ePub won't have any widt or height, and not even any dpi for pixels, Pages uses it. My book is 20 x 15 cm. So, the front page is inserted as a 600 x 450 jpg. I tell pages that it is "text bound" and that it causes break with zero extra size around. Then I set the size of the jpg to 20 cm, and it ends up as 19.99. Some 4 years ago when I did my first book I remember that this was a hurdle to find out. It may not be so stringent now. The front page is shown by iBooks in the overview section. Still I have also included it at the end of the book, so that people may see it there.
So, width is used to tell relative measures. To me, 20 cm is full width. 10 cm is half. I also think that a picture of full width is a page break, if there is no other reasaon to break the page.
2.2 Shadows
There is no shadows in ePub (is there in 3.0?). In this book the paper version used pictures with shadows. Just copying them across seemed ok, but of course there were no shadows. So, I took the jpg pages sent to iPhoto, cropped them to become wide but not full height and inserted them into the document. Now a pixel is a pixel, shadow or a pimple on the nose.
The first error I did was to insert the picture, then the text, then the picture as every other. Since the pictures were full width, they appeared correctly on a page. But then I increase the text size, so that some chapters were more than one page. My half/half system was broken, and it looked stupid with a picture after the previous, on the right side of the previous double page.
So, pictures were added as part of the text: on top of it. If I set the attributes as with the front page, Pages aligns it on the top for me.
All fine, the shadows went all fine.
But when I in iBooks on iPad selected night theme, all was broken, see right part here (I have obfuscated the text, as it has no relevance here):
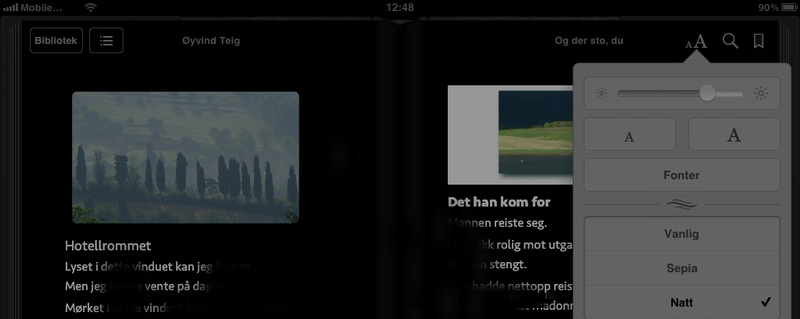
Of course the white background was white. Not very nice.
I had to revert to the old pictures as I had inserted them into the original pages document. I inserted them into a beatuful tool called Picturesque by a company called Acqualia, see http://www.acqualia.com/picturesque/. I have used it for years on Tiger, and now I have it for Lion. It exports with transparent background if you want it. Into png (jpg has no transparency). It also knows when shadowing is over, with no more pixels changed. Photshop Elements is not so nice. It's not nice when a soft shadow gets an abrupt stop. So Picturesque expands your picture as much as needed.
Then I used Graphic Converter to expand with 20% on each side. (I have mailed Acquila about this, if Picturesque could possibly save "with margins added". And got a positive reply.) GraphicConverter expanded transparent with transparent. Good. I want the picture not to fill the whole page (even if the file would). Then I rescaled to 600 pixel width and inserted into pages. You see the result in the figure above (left side).
That being said, shadows are problematic when there is no semantic knowledge. Picturesque would calculate the colours according to the background colour. It's more or less nice when background changes (as it will dramatically, with iBooks night mode). So, ePub should have had shadows etc.
2.3 File names of pictures and a Pages ('09 4.1) error
Before you add any pictures, make sure to name them with old fashined ASCII only!
The ePub file is a package of xml files and graphic files etc. When you drag a picture into Pages, it's just moved into the ePub package, with name and all.
I believe that the error with Pages that I discovered, comes from Pages trying not to insert a graphics file more than once (a hypothesis). So, it has to keep an internal list of included files. Most of my pictures were taken from my picture library, with files with names and places etc. (I don't use iPhoto for this). In Norwegian, where we have the three letters Æ Ø and Å (æøå). When I verified the final ePub (mentioned earlier), the verifier issued warnings with these file names. I hate warning, I always want clean results. Back to the drawing board.
So I inserted the pictures again, after renaming them. To my surprise I saw that Pages kept the old names. The file list must have also stored size and date, or at least some way where Pages would infer that what I inserted was the same file! So, if "same" file, no reason to change its name!
Then I tried to remove all the pictures, save pages and edit it again. Still the old names were kept! With æ ø and å. Impressing. I found no way at all to circumvent this!
I had no other solution than to start from scratch!
However, my backup with the jpg-files was good to have. I used it, and all fine. It did not believe that the jpg and png files were the same.
- Reported to http://www.apple.com/feedback/pages.html on 22Feb2012
- I also informed about this blog note at https://discussions.apple.com/thread/3755214.
After these reports I discovered another peculiarity: Pages may well keep the same name on two different files. This is possible by importing 12.jpg and then renaming the numbered list of file names on the outside so that previous 13.jpg now becomes 12.jpg. So, the next picture to import is 12.jpg, but a different picture than the previous 12.jpg. Either OS X handles this for it, or it has a file-indirection itself. Any way, renaming on the fly (in the Inspector window) should have been possible?
2.4 Alignment of chapter name below a picture
Chapter heading is, as mentioned, of style "Chapter name" in Pages.
I start every new chapter with a picture, as you may see in the picture above. Below the picture is the chapter name. Below or below?
I had given up getting this to show up correctly in anything else than iBooks in iOS. Stanza deliberately seemed to start the chapter heading immediately to the right of the picture, if it decided that it was space for it. To make a long story short:
Make the chapter name start with a soft enter (Ctrl Enter) and then write the chapter name.
Of course, this pushes the cursor to the left. The index works fine, it does not see any extra empty line. There is no extra page (as hard enter causes). In both iBooks and Stanza! And Adobe Digital Editions on the Mac (Lion)!
Ok, it appears below the picture. But it's left aligned in iBooks (iOS) and Adobe Digital Editions (Mac), and centered in Stanza (iOS). But it looks ten times better!
My ePub
You may download the one I have described here from this page (search for "ePub"): http://www.teigfam.net/oyvind/ogderstodu/. It's free from that page.
.
Monday, January 30, 2012
039 - Adding real-time processes to on/when programming?
This note will try to discuss if it is possible (or reasonable) to add safe real-time processes to systems like the nRFGo Studio by Nordic Semiconductor [1], or to the Echelon Lon-controller, programmed in Neuron C [2]?
(After having almost finished this note, it has swollen to show how a channel based system could be written, more generally.)
Neuron C is used in Neuron Chips and Smart Transceivers, where Network variables are fundamental to Neuron C and LONWORKS applications. The nRFgo SDK is a Software Development Kit for Nordic nRF24L Series 2.4GHz RF System-on-Chips (SoCs).
Both have event-driven (on/when) architecture. Add "safe processes" to already well tuned software and hardware architectures, what do I mean?
Should you follow this note as it develops, please warn me if I say something wrong. To say it shortly, I would know my mantra (write a CSP channel based process scheduler in C) quite well. Many blog notes, publications and invited lectures revolve around that theme. But nRFGo and Neuron C I have never had any experience with. I simply rememeber long ago (about 1995) when some collegues did use the Neuron C. I see it's still alive. And the nRFGo seems to have been written just up the hill from where I live, so I got curious.
I don't know if an nRFGo or Neuron C programmer would ever want or need a process term. Since it would be the first I would personally look for, I would even before that have a look at what's already there. I have programmed so much microcontrollers that I would know what an interrupt is there for. An interrupt function, is a sort of "process", since there is microcode (or whatever) to handle how it is able to set other functions aside, and later on return to the interrupted function the morning after. Only, the interrupted code slept without knowing it.
And I remember around the year 2000, when I was on a committee called RTJWG [3] (now defunct), how so much of the discussions was about how to connect asynchronous I/O to the Java language. I had programmed the transputer for almost ten years at the time, and it and the occam language didn't even have a separate interrupt term. All was processes. So, I really didn't understand why they were discussing this so much then. I also remember a programmer I worked with back in the early eighties who got that part almost all wrong, and a collegue had to spend a year dismantling and collecting the assembly code back again. The part of the product that had a run time scheduler (a separate board and processor with code also written in assembly) worked from day one (in the asyncronous I/O and process term context). We got it all working according to specs before some Swedish nuclear power stations had to rely on the system.
Here comes on or when programming, to deliver a framework to connect interrupts (or all internal events) to non-interrupt code. Or to decouple the two. It might not be a good idea to do an FFT in the interrupt, it may be better to just pass over the data and let some other code do it later on. The sooner the better, probably - but not in the interrupt. The interrupt would have some hard real-time schedule to it, like get it over in 20 us, because there are other interrupts, you know.
In nRFGo there already is an on (like on_pipe_updated or on_transaction_finished) and a subscriber term, and there is a dispatcher for handling of events and communication between different modules. I will later try to figure out what a module is, and what a transaction is. The nRFGo uses the Keil compiler, probably wrapped up by some tools that they developed in Qt. I think their Help tells me this. So, they seem to have a C compiler there. Even if their tool also builds code by the set-up config, the user has C available. After ARM bought Keil, the ARM suite was moved over to the Keil IDE. But Nordic lists the Keil C51 C compiler, so the core must be C51 based.
In Neuron C there is a when, and events are used in when-clauses to enable the execution of a when-task, using a special syntax. A when statement can contain more than one when clause.
I think these two mechanism basically do the same: deliver a framework to connect asynchronous I/O to the rest of the code.
Scheduler and dispatcher
nRFGo contains a dispatcher, and Neuron C a scheduler. The Wikipedia article says that a scheduler typically decides which process is running, while the dispatcher makes it running [4]. This note will not be precise about this, as it is rather difficult to distinguish in a microcontroller. nFRGo and Neuron C will do about the same, with different wording - even if Neuron C's scheduler also have preemption mode.
Towards a process model
The modules or tasks mentioned are meant to be independent subscribers to defined services. In a way they are a means to order the asynchronous I/O.
However they don't seem to be processes as I would think of them. I will try to explain.
They are closely connected to the hardware in the processors. None of the code would be portable. I remember when we wanted to port some embedded code that implemented a software UART from an AVR to and ARM, I wrote an interpreter below the hardcoded use of registers in the AVR. So, on the ARM, the interpreter picked up bytes at named memory locations and wrote back. And the oversampling represented in the UART and its use of timers, input capture and output compare registers etc. was handled with a single timer interrupt on the ARM. We didn't change a line of code on the AVR, and the ARM addition was a layer below. This layer handled two usch UARTS, one more than was available in the AVR.
The more some code handles particular hw in the processor, the less it is portable. The sw described in this note connects to that hw alone. Nothing else, as far as I can see.
There are no independent processes or tasks that may talk with each other, and have a life of their own. And since these are not defined, there is no communication or synchronization model either.
One of the Lon chips "also supply one binary semaphore to support synchronized access to shared resources between the application and the ISR processor". This is interesting, and probably very useful. But it does not add the process model I am looking for.
The process model
The process model I would suggest to add is "standard" CSP type processes with safe buffered channels. I have used much of my professional life with this model, starting with the occam language. I have also published a lot about this. Blog note 034 has something about buffered channels. Add this paper (it's also [5]), and you'd have a good starting point. I will not re-refer to these papers. There will also be rationale for this type of programming in those references.
It starts to dawn on me how difficult this note could become, or has become. I had not thought that I should include the code to anything like BufChanSched (buffered channel based process scheduler), you must do it yourself. But maybe my writings could be of some inspiration.
In my experience this model is useful both for typical data-flow dominated systems (like regulating systems and more process-oriented designs) as well as control dominated systems (like drivers or protocols). And then, most systems I have seen are a mix of both styles.
The process model by how to make it
Still, here are some points (which basically says a lot about the process model):
- A process is a C function. Start all process names with P_.
- Make a list of pointers to those functions.
- No static variables in the functions.
- No reference to external variables except the channels it uses.
- A channel sends data and is basically blocking. The second on the channel (sender or receiver) continues to run, while the first becomes ready.
- A channel sends signals (with no data) asynchronously (never blocks).
- A buffered channel never blocks, but always returns an ok/full bool. When it's full the scheduler uses a channel ready signal channel to tell that the channel again may be sent to
- A channel input may define three types of timers: ALTTIMER, EGGTIMER and REPTIMER.
- If you need to pass parameters to a function, there is no way to do it in C. Since it's going to be called by its pointer when it's scheduled, adding parameters may be done with some kind of table. But this is most often not needed for a small scheduler in C. Since there is no language support, it's possible to get around it.
- ...
- You need a standard scheduler in C, that keeps a list of the entry points to all processes. The entry points are assigned once only.
- A process has initialization code, and a "while (true)" loop.
- It has a "proctor table" described in the reference above, that by a simple, hidden goto gets the process to any rescheduling point. See here.
- A process has only one reason to be scheduled.
- A process may send on a channel, but there is no output guard.
- A process may receive on a single channel.
- A process may wait on a list of channels in an ALT. Each component may have a boolean guard to that it's easy to switch this on and off in the process. If false that component is skipped. When one component of the ALT has become activated (is that the word?), then the ALT is torn down, so that all the other entries's "first" state is nulled.
- You could start "individs" of each process, but then you would have to parameterise the channels.
- Each process has a struct of local variables which is allocated on the heap by a malloc in the initialisation part. Call this the "context". This is never freed, so it's easy to know if you have overflowed.
- ...
- A simple return from the process code gets you down to the scheduler. Therefore, no blocking calls are allowed from any subroutine level.
- When the scheduler finds no cause to schedule a channel or there is no channel waited for, there is a system fault. You probably have a deadlock.
- To avoid deadlock, use a deadlock free pattern, like knock-come from blog note 009.
- No external functions may call any function in a process file (except the scheduler).
- The process context is local to a process, and not seen elsewhere. Only parts of it are exposed to the channel (place and sizeof).
- Two processes may call a common function, since this scheduler is not preemptive. But do it seldom, and in no case let that function have any side effects. This means that it cannot alter common state (like registers or static etc.). The exception is all channel handling, ie. all scheduler functions. Of course it has system side effects, but not application side effects.
- Channel size is dynamic, but the sender and receiver must agree. So a common protocol definition header file must be made. A protocol is a collection of structs with tags and data.
- With this system communication and synchronization is the same. If you use buffering, it may become the same.
- Channel names are handled by en enum, values from 0 to n. Channels may have to be initialized. I do it in a separate function, that would init all.
- ...
- Coding the ALT is the most complex, because you may need a bitset (any primitive word size or array), used by each ALT to represent the ALT set. An ALT is "built" or "tore down". You need it so that the first that arrives on the channel, only refers to that bitset to tear down, with no knowledge of the other components.
- If you need "fair ALT", then you could bundle the ALT set in an array, and start the ALT with an index which is one more than the one just "taken". The index needs to wrap around in modulo n
- If you need processes to have priority, think twice (priority inversion etc.).
- If you have thought twice, make one ready queue for each priority.
- But maybe you would rather think of channels as the means to supply priority. Should they instead be prioritized? But do think twice on this too.
- If you do need priority, play on team with the interrupt functions. The chip designers would have thought out a scheme for you.
- Use macros to make it code better readable and hide parameters that don't need to be seen. But be aware of limitations, like Neuron C does not support #if or #elif. The synchronization points described in [5] uses labels thas absolutely should be invisible.
- ...
These points are well documented in the literature. But a list like the above may still be ok.
So what about nRFGo and Neuron C?
The challenge is to add a small and safe run-time system with light-weight processes to these already small systems. A hypothetical BufChanSched would probably just add a few kB of code, and around 10 bytes per blocking (zero-buffered) channel. Process overhead is also small in code and RAM. And scheduling and rescheduling is light weight, smaller than interrupt context switching.
Maybe it would be nice to have processes available also for the application code in a radio chip like nRF24LE1 or the networking Neuron chip?
Perhaps someone could make an open source project for a pluggable channel based scheduler? With it, the (right) process model comes creeping all by itself..
..provided you also have a glimpse at where it came from: occam and occam-π. And assure your boss (and/or better half) that it's not going to be a waste of knowledge, as these days you'll even make a sneek peek into some of Go.
References
[1] - http://www.nordicsemi.com/eng/Products/2.4GHz-RF/nRFgo-SDK. Is there a public manual like the Neuron C manual? So I have guessed my way.. However, there is a little used public talk forum, see http://www.nrftalk.net
[2] - http://www.echelon.com/support/documentation/manuals/devtools/default.htm (Search for "Neuron C")
[3] - Real Time Java Working group, J Consortium (Java Consortium) - (NIST), backed by HP, Microsoft, Newmonics. All remains of this seem lost. Of course, the Sun based initiative JSR-1 won (http://en.wikipedia.org/wiki/Real_time_Java)
[4] - http://en.wikipedia.org/wiki/Scheduling_(computing) dispatcher / scheduler
[5] - "New ALT for Application Timers and Synchronisation Point Scheduling" by Vannebo and Teig. See http://www.teigfam.net/oyvind/pub/pub_details.html#NewALT
.
Sunday, January 15, 2012
Tuesday, December 27, 2011
036 - WYSIWYG semantics
This blog note has been moved to http://www.teigfam.net/oyvind/home/technology/079-wysiwyg-semantics/ on 17Jan2014
Monday, December 19, 2011
035 - Channels and rendezvous vs. safety-critical systems
New 19Dec2011, updated 3Jan2017
Moved to http://www.teigfam.net/oyvind/home/technology/035-channels-and-rendezvous-vs-safety-critical-systems on 11April2017
Moved to http://www.teigfam.net/oyvind/home/technology/035-channels-and-rendezvous-vs-safety-critical-systems on 11April2017
Saturday, December 3, 2011
034 - Output guard vs. "channel ready" channel
Last edit: 16. August 2012
On the airplane home, the other day, I came upon an idea that I thought would make life easier. When I told a guy at work, he said, "oh, it's already in Linux".
I assume that you're somewhat familiar with "channels". In this respect I was raised with the occam language. (You would find Wikipedia-articles for most of the names I'll throw here. So I won't get too deep into some details.)
Here, a channel is based on CSP (later), and it is one-directional, non-buffered and blocking. It's even one-to-one. It connects tight processes to each other. It also allows threads to be equally tight. So, the first process that comes to a channel (be it sender or receiver), must be descheduled and not ever run again before the second process arrives on the channel. At that time there's a memcpy of the correct data from the sender's private context, to the receiver's matching field. It is possible to make it type safe. The message is passed across, while both sender and receiver are still. In Ada it's called a rendezvous. In Go it has no name. When the memcpy is done, usually the second on the channel just runs on, while the first is put in the ready-to-be-scheduled queue.
There is a mechanism called on ALT or a "select", where a process may wait for a number of (input) channels. A channel may be with data, without data, or timeouts. In my world (opposite to Linux select), there is exactly one cause that may trigger the SELECT. I will use capitalized "SELECT" here to cover any such idiom, to differentiate from the Linux "select". The first cause that triggers the SELECT will be stored and cause a later rescheduling, but any potential causes that "lost", will not be allowed to cause an additional triggering. Only one cause per scheduling of a process. Very different from Linux select.
Said differently: the SELECT will put all the channels in the set to "first was here". When the first "second" contender on a channel in the set arrives, all the "first" attributes are removed from the rest of the set. This is a beautiful algorithm, that I think was first implemented in microcode on the first transputer processer in 1984. Inmos in Bristol, UK, made it, and David May and Tony Hoare (the father of CSP, "Communicating Sequential Processes" process algebra) were the main architects. The transputer basically was a machine designed to run the subset of CSP that was called occam. It's 28 years ago. Ada based its concurrency model on CSP. And 26 years after occam, Google designed the Go programming language, which also has based its concurrency model on CSP, just like the same guys had done at Lucent some 10 years before with their Limbo language. Except, at that time they didn't state the roots of their "chan of protocol". And transputer designer David May now is active with a company called XMOS, and a language called XC, based on the same ideas. So, CSP-based concurrency seems to be increasingly coming.
With this scheme communication equals synchronization.
In CSP they talk about "choice". It may be deterministic or "external" or nondeterministic or "internal" (often written as [] and |~|).
The SELECT is for the teacher who assigns work to his students. He then falls to sleep (or does other things) and is awaked when the first student is finished. The student is then served, and the SELECT is entered again. The new set may include the first student, when some fair scheme is used to avoid him spam the teacher. Or the SELECT may be non-deterministic. Read in the literature, f.ex. the Promela Wiki-article (more below).
With this scheme, the teacher may say that one of the students is not allowed to deliver his result before after two hours. So, there may be timers in the SELECT set. This would also make busy polling possible, should this be needed at the application level. But the run-time scheduler NEVER needs busy-polling. Another way to say this is that a process always has a cause when it's scheduled. Just think about Java's notify and notifyall, which may schedule a process for no reason!
Also, there may be an INPUT GUARD for each channel (applied to our special student for two hours). This is usually implemented as a conditional to each member of the SELECT set. Think of the SELECT GUARD set as a bit-mask, one bit per element in the set, just like in Linux select.
Now I'm getting closer to the theme of this note: Output guard vs. "channel ready" channel.
Some times it's required to buffer a message on a channel. In occam we used to do this by inserting a single buffer process, or a couple of processes to make one composite process called an "overflow buffer", which made it possible to detect a too eager producer and associated too slow consumer - at this application level. One time I needed a buffer of a hundred buffer positions, and I just started 100 buffers. Easy! The downside was that there would be 101 memory copies, so most often a ring buffer was administered inside the first of the two processes in the composite overflow buffer process.
The alternative could be for the eager producer (it has no idea itself how eager it is) to have something called an OUTPUT GUARD available. If you want to see it, have a look at the Promela process meta language (Wikipedia). This way, both inputs and outputs may be collected in the SELECT. So, having just one channel, plus an "else", then the potential receiver, if it is able to receive, will inform through the output guard if it's ok to send. If not, the else will be taken. The SELECT with both input and output looks like the Linux select, but that one doesn't have the synchronized mechanism in the bottom.There is a code examples in [6] (here, search for bufchansched).
It's a nice mechanism. I have never had it in my world. It was not implemented on the transputer, since it was a multi-core programming language. And implementing it across a network (links) presumably was not worth it. There was another mechanism to get the same functionality. If you know what mechanism, please comment.
An output guard mechanism is good for detecting a broken line. To detected a connected line, there would have to be polling. Busy polling is most often necessary for this (assuming no hw edge interrupt). But the output guard seems not so relevant to handle the fast producer, slow consumer scenario - between internal processes. The same broken / connected scenario also would go for detecting that the other process has stopped, for some reason. Perhaps enough for a new blog note here.
So, here's the solution, to avoid the output guard, to avoid busy polling. The solution that also almost exists in Linux.
A standard channel has zero buffers. Have a look at Promela and Go. They both support buffered channels. So, why not add them to [1]? What should happen when such a channel is full? The channel send just returns a flag saying that it’s full, and the channel would not block in that situation. Observe that blocking is perfectly ok and does not impact what a system is able to do. With enough "parallel slackness" to get all the I/O going at required speed, having a process block (waiting in a non-busy way, for the second to arrive at the channel). But for a driver, close to the "asynchronous world" it's nice not to block to get rid of incoming messages. And it's nice not to send it into an asynchronous message system that may plainly overflow, crash and restart. We need a better system. We need the driver process to not block in that situation and itself handle overflows.
So, in the suggestion, after the return of the buffer full flag, the process knows this and if any incoming message arrives from the external asynchronous world, it may set a hold line, send a hold message or throw away the message - or whatever it decides to. It's up to the process.
In this state, the process will SELECT around a timeout channel and this channel that's triggered by the run-time system, that arrives when there is room in the channel. The receiver has picked out one message or all, that semantics is not so important here.
When this "channel ready" channel fires, the process can send off the last message, which may also be tagged with an overflow bit, on the channel. And it's guaranteed to succeed (unlike in Linux).
I was rather satisfied by inventing this on the plane home. I didn't like that it was already in Linux write and select. I have tried to describe some of the dissimilarities. See [2] for write, EAGAIN or EWOULDBLOCK and [3] for select (or pselect) and fd_set *writefds. It's in the context of writing to a Linux pipe.
But please, could anyone help me with describing how my solution is much "thread safer" than Linux? I need more than this:
I have more of a language, since I would do as described and reasoned above. Linux calls and Linux processes and threads are not understood by C or C++. Up to C++11 at least. And only so much understood by Linux. A C++ library for Linux needed several mutexes and semaphors to implement an ALT/SELECT in the CSP context [4]. So, are write and select usages in Linux really thread safe? I have a scheduler that is driven by the channels, and it's not preemptive. And why do Linux programmers brag that they "program single-threaded"? Is it an indication that the Linux process model is too coarse or difficult or expensive? So that they haven't learned to decompose into processes, when there is state or roles to hide away into a separate process? After object-orientation or OO, it's time for process-orientation as an additional idiom.
Should have been fun to set up a comparison table of the CSP type SELECT with channel ready channel and the similar Linux solution. Even if they are both fruits, I fear that one is apple and the other bananas?
A Linux pipe vs. channel trait
Observe that a Linux pipe is byte-wise. You send so many bytes and then so many bytes, and they are concatenated in the pipe. There has to be a common view of how to pick out each message or token.Common usage of Linux select
This implies that you could read past a token, since a sender may have to break up a message into several chunks. There is no foldback, you cannot push anything back again. So, the receiver has to keep track of these things.
A channel is message based. A full message per chunk. Finito.
A collegue told me that the common usage of a Linux select is to remove active polling for events from remote machines from the application level, in say a http server (router). He said that he always used select to wait for events on already open sockets. One socket per bit in the select bit map."My idea" - again
Internally between threads he never had used select.
And he rarely used ip addresses internally between processes, so no select there either.
I found an interesting sentence in [5]. Here is its process-oriented specification of a buffer: If a buffer is empty it must be ready for input. If it contains some messages, then the buffer must be ready to output the next message required. It is also possible that it will accept further input, but it does not have to. (my comment: is this buffer full?) But here is the interesting sentence: "If further events are to be possible (such as a channel which can report on whether or not the channel is empty), then...". This is "my" channel! I am even more convinced now, that "my" idea was quite good!Epilogue: "The XCHAN paper"
During June and July 2012 I had the opportunity to channel this blog note into a full blown paper for the CPA-2012 (at University of Abertay Dundee, Scotland 26-29 August 2012). I have published for the WoTUG and CPA series conferences several times before, but this time it was especially exciting. See [8] and here:
XCHANs: Notes on a New Channel Type
Øyvind TEIG, Autronica Fire and Security AS, Trondheim, NorwayAbstract. This paper proposes a new channel type, XCHAN, for communicating messages between a sender and receiver. Sending on an XCHAN is asynchronous, with the sending process informed as to its success. XCHANs may be buffered, in which case a successful send means the message has got into the buffer. A successful send to an unbuffered XCHAN means the receiving process has the message. In either case, a failed send means the message has been discarded. If sending on an XCHAN fails, a built-in feedback channel (the x-channel, which has conventional channel semantics) will signal to the sender when the channel is ready for input (i.e., the next send will succeed). This x-channel may be used in a select or ALT by the sender side (only input guards are needed), so that the sender may passively wait for this notification whilst servicing other events. When the x-channel signal is taken, the sender should send as soon as possible -- but it is free to send something other than the message originally attempted (e.g. some freshly arrived data). The paper compares the use of XCHAN with the use of output guards in select/ALT statements. XCHAN usage should follow a design pattern, which is also described. Since the XCHAN never blocks, its use contributes towards deadlock- avoidance. The XCHAN offers one solution to the problem of overflow handling associated with a fast producer and slow consumer in message passing systems. The claim is that availability of XCHANs for channel based systems gives the designer and programmer another means to simplify and increase quality.
References
[1] - http://www.teigfam.net/oyvind/pub/pub_details.html#NewALT
"New ALT for Application Timers and Synchronisation Point Scheduling"
Øyvind Teig and Per Johan Vannebo
Communicating Process Architectures 2009 (CPA-2009)
Peter H. Welch et. al. (Eds.)
IOS Press, 2009, ISBN 978-1-60750-065-0
[2] - http://linux.die.net/man/2/write
[3] - http://linux.die.net/man/2/select
[4] - Search for "C++CSP2"
[5] - Concurrent and real-time systems. The CSP approach. Steve Schneider. Wiley, 2000. Page 210, example about buffers (7.4.1).[6] - Lecture at NTNU, Trondheim in April 2012: http://www.teigfam.net/oyvind/pub/NTNU_2012/foredrag.pdf - search for "bufchansched", since it's in Norwegian[7] - Communicating Process Architectures 2012 (CPA-2012): http://www.wotug.org/cpa2012/. Full programme: http://www.wotug.org/cpa2012/programme.shtml[8] - "XCHANs: Notes on a New Channel Type"Øyvind TeigCommunicating Process Architectures 2012.Peter H. Welch et. al.(Eds.).ISBN (later)
.
.
.
Subscribe to:
Comments (Atom)
Popular Posts
-
This note is updated at my new blog space only, blog note http://www.teigfam.net/oyvind/home/technology/050-sound-on-sound-and-picture/ ...
-
Canal Digital og hjemmenett ("bredbånd") Dette er et lite notat om hvordan du kan konfigurere ruteren din dersom du får internett ...
-
New 19Dec2011, updated 3Jan2017 Moved to http://www.teigfam.net/oyvind/home/technology/035-channels-and-rendezvous-vs-safety-critical-sys...
-
This blog will show how a table intensic page (my home page at http://www.teigfam.net/oyvind/ ) is rendered on the iPhone by Safari and Ope...



{kind=link}
Øyvind Teig

- aclassifier
- Trondheim, Norway
All new blogs and new home page start at
https://www.teigfam.net/oyvind/home
Overview of old blog notes here
My technology blog was at
https://oyvteig.blogspot.com
and my handicraft blog was at
https://oyvteig-2.blogspot.com
PS: just call me "Oyvind"